This post is one in an ongoing series (starting here) in which I am developing the concept of 'Informational Identity'. Your name, your legal identities, your digital identities, are all the same kind of thing: information tools created to pick you out of a crowd, to refer to you when you are not present, to bind your will to virtual worlds. These Informational Identities are related to each other in a directed graph whose nodes are privilege domains and whose edges are the authentication by the 'tail' nodes of credentials issued by the 'heads' for the credentials' secondary purpose: demonstrating that the issuers were satisfied at the time of issue that they knew who you were.
In my last post, Identity: Turtles All the Way Down, I described our Informational Identities, which include both our legal identities and digital identities, and which we can model as directed graphs of managed resource domain nodes connected by credentials and their validation.
Let’s dissect the nodes and edges a little more deeply, wielding logical necessity as our scalpel, to try to reveal more about their natures.
A user, an agent – I will use those synonymously – comes to a resource domain with their existing Informational Identity looking to use the resources. The user may be granted free, unencumbered access to the domain. In this case there is no direct binding to their Informational Identity. (There may be indirect binding if the domain is tracking the user by some means and that trail leads to the user’s Informational Identity. For example, a site may be able to get to your Informational Identity via a device identifier from your cell phone.)
Why does a domain owner introduce gated access? It gives them an opportunity to qualify the applicants and selectively admit them. We don’t want just anyone in the country club, do we? Identity proofing may be part of the qualification. There may be additional requirements, such as proof of income. Some of those may piggyback on identity proofing, such as checking your bank balance. Others may not – a big enough bag of Kruggerands might get you in : ).
Gated access lets them structure access to the resources in their domain – they can group the resources into bundles. Which lets them grant a user privileges selectively to one or more of the bundles. These members have golfing and gym privileges, those members only gym privileges.
In gated access, an applicant requests credentialing from a domain owner to gain authorization to do something. They request a membership card to be authorized to play golf. They request a driver’s license to be authorized to operate a motor vehicle on public roads. They request a Facebook username and password to be authorized to create and maintain a Facebook page.
The domain owner creates a mapping associating the credentials with the granted privileges. The only thing that is logically necessary to enable the basic functionality is that the credentials map to the privileges.
The domain owner does not need to store demographics about the user. They may have asked for demographics as part of qualifying, of identity proofing, the user. But they don’t have to persist those demographics to enable the basic function of mapping to privileges.
Credentials don’t have to be unique to perform their basic function. The domain owner could hand out Queens of Heart and Jacks of Spade and selectively map those to privileges to gamble with the high rollers or the hoi polloi.
These kinds of ‘mass’ credentials may still bind to our Informational Identity if credentials from one or more Informational Identity nodes are used at proofing. A downstream domain owner may in turn use the credential as part of their own identity proofing, connecting the nodes and building the Informational Identity graph.
All the Queens of Hearts holders’ Informational Identities are also connected in the aggregate. That is, if you have a Queen of Hearts credential for GambleYourLastBuck.party, assuming Informational Identity binding at proofing, yours is one of this set of Informational Identities.
At this stage, the identity records kept by the domain owner are not only anonymous, they are not necessarily unique.
Why would a domain owner want credentials to map uniquely to a set of privileges, that is, why would they want credentials to be unique? (If more than one credential, it is sufficient for either or the combination to be unique versus others.)
It gives them the ability to distinguish one user’s admission and resource use from another’s.
Which in and of itself is of limited utility to the domain owner using only the primary utility of credentials, gating access. It lets them report on unique users per some period and log ins per user per some period. It enables them to analyze access by groups of users with common privileges. Such groups may be combined logically – and, or, not, xor – into other groups.
But mostly it paves the way for two additional functions of great interest to domain owners: communication with users, and demographic-based analytics.
The domain owner may obtain and may maintain communication keys – unique addresses for a given medium, such as email addresses, voice phone numbers, SMS phone number, and so on.
These keys are unique in their domains, but not necessarily unique to a given user: users share emails, share phone numbers, share street addresses.
Domain owners capture demographics to enable them to slice and dice their individual user analytics on demographic axes.
These are still individual domain users at this point, not necessarily individual Informational Identities. Because an individual might have more than one account at the same domain. (I have two Yahoo email accounts and two Gmail accounts, and one petty Hotmail account I only use with Zynga games which, if you read the email address out loud says something rude about Zynga for requiring me to give them a valid email address to play Words with Friends).
So at this point, a domain can’t analyze the behavior of unique Informational Identities at their domain, or ensure a domain user only receives one of a certain kind of communication, and so on.
There are two things they can do. Both demand identity matching. The first is to enforce each user has a unique Informational Identity on registration. The second is ‘fix up’ the data for operations and analytics after the fact by identity matching on the backside.
This is where things start to get hairy. To enforce unique Informational Identity accounts, you (or the IdP you have outsourced this to via federation) could try just persisting enough information about the credentials whose secondary utility is being accessed at proofing to know you have seen them before, such as a driver’s license number. But if their choice of credentials at proofing is flexible – say they showed you an Oregon driver’s license the first time, and this time they are showing you a US Passport – just persisting the driver’s license number or passport number won’t do.
You would have to capture demographic data about the individual from their credentials or the issuers at proofing, and search the demographic data you have already persisted for matches before creating a new user account and issuing new credentials.
But if you have an existing record for them, you may have to go through the operational process of re-credentialing them for that record.
To recap, identifying individual agents is not necessary to gated resource access. An identity record in the conventional sense, that is, one with demographics, is not a necessary function of gating access to a resource domain. Domain owners capture demographics and communication keys in order to operationally communicate with users, and to track and analyze individual user behavior. If they want to track unique Informational Identities, not just individual users at their site, they either have to search for ‘duplicate’ Informational Identities at registration, or match and integrate the user accounts internally after the fact.
What about the username, the most common feature of digital account access? A username is fundamentally a type of credential. It is generally unique within the managed resource domain, and insofar as it is it serves on its own as a rigid designator pointing to the user. But usernames are not necessary. A domain could manage access via a single credential, such as a password, with no username, and as long as the password was unique across the domain it would serve. A username and a password are two credentials – we have been doing multi-factor authentication all along.
But it is convenient for both the user and the site to have a username which rarely, if ever, changes, and to imbue it independently of the other credentials with the ‘deicticity’ – the ‘pointing-ness’ – function in the identity record: user maxftempleton is _that person_, no matter what their current password (though if that person wants to exercise their privileges they need both credentials, username and password.)
Here is a picture to capture the stack of access types we have discussed.
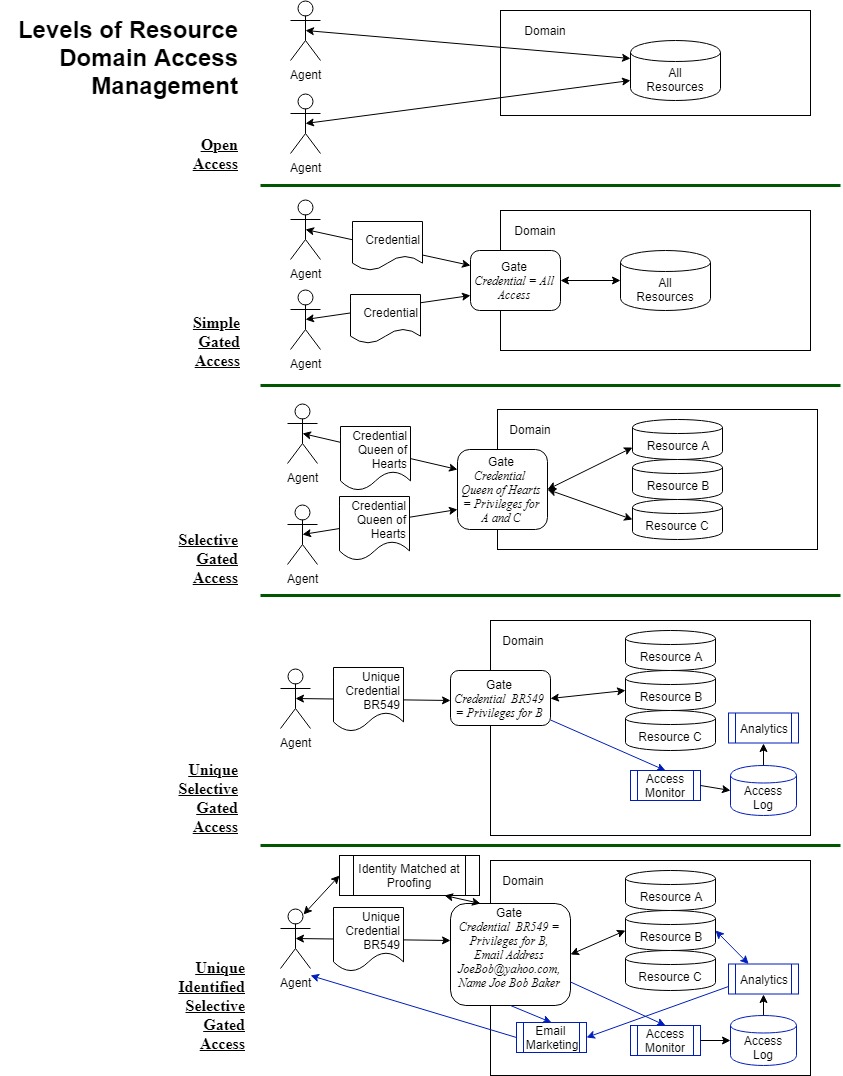
So where have we gotten to in our further analysis of the Informational Identity graph?
The ability to add to an Informational Identity graph is not a function of the nature of the domain gate records themselves with respect to whether they are unique, contain demographics, etc – it is a function of the upstream credentials required in proofing if any. Therefore the nodes in our Informational Identities represent gated resource domains, not necessarily managed identity domains, as I implied in Turtles. Many if not most of those domains do maintain demographic ‘identity’ data. The use of credentials from upstream gated resource domains used in identity proofing is what binds our nodes together. Identity ‘streams’ through the Informational Identity graph along the edges. It does not necessarily inhabit the nodes themselves.
Attribute-based patient matching is problematic in large part because of the contingent role user demographics plays in Identity, Credential and Access Management. As we have seen, demographics are not a necessary part of ICAM. They are captured to serve the varied analytic and communication needs of domain owners, not identity needs. If they are kept at all, there is no requirement for accuracy or completeness. Such attributes are always point-in-time snapshots which are at risk of becoming out of date as soon as they are captured.
Requirements for standardizing the attributes and their domains will only get you so far in improving patient matching. The provenance of the attributes must also be tracked. So-called ‘referential’ matching is really two distinct features, the ability to match historical attributes, so that ‘stale’ records still have probitive value, combined with the hub-based aggregation and maintenance of such history from some set of ‘authoritative’ sources – which we assume means strongly-proofed gated resource domains.
There is one more reason resource domains capture demographics.
A user is legally and morally responsible for their actions in a domain. If I am admitted as a guest at Augusta National and tear up the 11th green at Amen Corner, it’s on me, on the member who got me admitted, and on the Augusta National employee who authenticated my human credential and their credentials. But they have to be able to bind to my legal identity to prosecute me. Unique agent domain access gating is a one way street without linking the identity to the individual’s Informational Identity.
If I log into SecretWhiteHouseFootballApp.gov and push the button to launch the nukes, the post-apocalypse war crimes tribunal is going to need to be able to find me. Of course, if I used repudiatable credentials to log in, I just might thwart justice. Stay tuned.

One thought on “Identity, Credential and Access Management Isn’t Exactly About Identity”