This post is one in an ongoing series (starting here) in which I am developing the concept of ‘Informational Identity’. Your name, your legal identities, your digital identities, are all the same kind of thing: information tools created to pick you out of a crowd, to refer to you when you are not present, to bind your will to virtual worlds. These Informational Identities are related to each other in a directed graph whose nodes are privilege domains and whose edges are the authentication by the ‘tail’ nodes of credentials issued by the ‘heads’ for the credentials’ secondary purpose: demonstrating that the issuers were satisfied at the time of issue that they knew who you were.
So far we’ve looked at the identifiers in our Informational Identities – Informational Identifiers are knowledge tools used by others, as I said in my last post, “to point to you, to pick you out from the field so that communication may be directed to you, to refer to you in communication, to granted you access to and/or privileges in some gated domain, to hold you liable for your actions in some legal domain.”
Your demographics, your relationships, your transactions – let’s call all that your ‘personal data’ for now – are not a logically necessary part of that lattice of tools.
How does your personal data come into the identity picture?
The owner of a gated privilege or resource domain may require that personal data to inform additional gating criteria during identity proofing above and beyond the upstream credentials they require.
The owner may also insist on persisting a snapshot of that personal data to use to communicate with you and about you, or to enable them to analyze their users’ behaviors by dimensions such as age, gender, and purchasing history.
If the owner wants to validate their record of you is unique, they could persist the identifiers used at proofing such as a driver’s license state and number or a passport country and number.
But they could instead, and more often do, demand your presentation of personal data so they can search for an existing individual in their records with that same profile.
And while personal data is not a logically necessary feature of an identity credential, many legacy credentials such as drivers’ licenses contain snapshots of part of it, such as your birthdate, gender, hair color, eye color, weight, and address, revealing it to the owner of the new domain to which you are seeking access.
Domain owners may also turn to third party sources for additional personal information.
Let’s dig into that personal data so we can better understand its nature and integrate it into the conceptual picture we are building around Informational Identity.
To do that we need to go back and look at the nature of personal identity.
That is a journey through philosophy, and it’s easy to get wrapped around the axle – personal identity is and has been a life’s work for many philosophers. I mean them no disrespect when I run roughshod through a couple of millennia of their work in a few paragraphs – they aren’t seeking practical software solutions, and have time to ponder arcane thought experiments (‘say we erased all your memories, and replaced them with the memories of the Civil War general Ambrose Burnside. Who are you now?’) to find conceptual edges.
Underlying personal identity is just plain old identity – what is usually called ‘numeric’ identity, e.g. ‘the relation everything has to itself and nothing else’. That trail leads through a pantheon of philosophers such as Locke, Frege, Quine, Kripke (again – some future historians will look back at him as our Lebniz) to, more recently, E.J. Lowe (cf ‘More Kinds of Being’ et al.) But with respect to any kind of actionable clarity, that path grounds out for me at ‘sortals’, which you know when you see but slip away (in circles) you try to grasp.
We need a handle to grab, a useful, practical philosophical perspective on personal identity we can use to inform our conceptual solution space.
I find it in the work of Paul Ricoeur and Daniel C. Dennett, two philsophers who could not be more different. But they both, independently, arrived at the idea that our personal identity, our self, is the center of narrative gravity of our story.
Imagine we had a detailed, up-to-the-moment story of your entire life as told by an omniscient narrator (I hear it voiced by Morgan Freeman).
Starting when you become a conscious being (a little hand-waving here around where in the conception->birth->first-person self-awareness->reflective self-awareness->objective self-awareness continuum your story begins), the narrative would capture and describe all of the changes over time to your inner states, such as emotions and beliefs, and outer states, such as location, height, hair color, and marital status.
In his broadly syndicated comic ‘The Family Circus’ Bill Keane frequently illustrated young Billy’s adventures with the now famous dashed line:
You are the protagonist of your own little Billy story. Your personal identity may be usefully seen for purposes of identity management as a narrative construct.
But the attributes of your personal identity can only be known to others in two ways: directly by the intersection of your narrative with specific instrumentation and observation; and indirectly by the reporting of those observations by you or other observers. Your inner states may be inferred by others from your outer states, but may only be definitively reported by you. (Please refer to my separate thread elsewhere in this blog on the nature of knowledge work for more context on the relationships of change, instrumentation, observation and reporting.)
So what another agent knows of your personal identity is necessarily a snapshot captured at such an intersection, or reported to them by another observer. That snapshot grows less accurate over time, with different attributes ‘decaying’ at different rates depending on their volatility. Your location changes quickly, your address more slowly, your name more slowly still.
The idea behind so-called ‘Relational Matching’ in the identity matching space is to capture the punctuated narrative history of key demographic attributes over time and use it to facilitate matching point-in-time snapshots. More on Relational Matching later in the Identity Matching thread that will be posted here.
The direct instrumentation and observation available to a given domain owner varies, as does the reporting they may receive from other observers.
In the instrumentation, observation, and reporting of the snapshot – its provenance – error can creep in. The snapshot any given domain owner has may be incorrect in one or more particulars.
Here is what our Informational Identity picture looks like now from the perspective of a single resource or privilege domain owner:
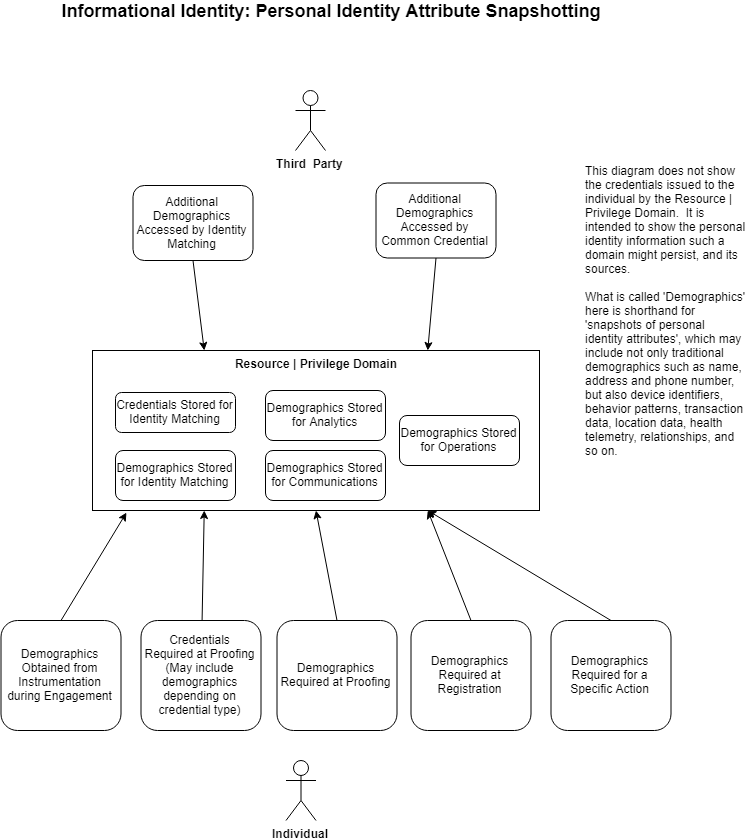
Next up we will look at responses to these increasing personal privacy issues in the identity domain from the perspective of the conceptual context we’ve built so far. Stay tuned.
